Como eu consegui mais de 6000 e-books gratuitos da Amazon com JavaScript
A Amazon está oferecendo uma enorme quantidade de e-books gratuitos nessa quarentena e neste post eu vou te mostrar como programar um script para pegar mais de 6000 e-books gratuitos por você, a menos que você queira pegar um por um na mão



Este post explica tudo o que eu fiz no vídeo publicado no meu canal do YouTube e de quebra você ainda vai aprender vários conceitos sobre JavaScript com atualizações vindas com o ES6, Requisições HTTP, a vulnerabilidade CSRF e muito mais. Caso você queira ver o vídeo antes de ler o post, basta clicar no play abaixo. Mas não deixe de ler este post, pois aqui você irá encontrar informações extras e mais detalhadas sobre as explicações do vídeo.
Primeiramente digite no Google “ebooks gratuitos amazon” e entre no link com o título “eBooks Gratuitos - Grátis na Amazon.com.br”.
Nesta página você verá uma lista com 16 livros e no final dela, ao observar o menu de paginação, podemos perceber que existem pelo menos 400 páginas de livros gratuitos. Dificilmente você vai querer visitar as 400 páginas para pegar os 16 livros de cada uma.
Existem duas formas de se obter os livros, a primeira e mais simples é clicando no botão “compre agora com 1-Clique”, o livro será registrado automaticamente na sua conta. A outra forma é para os livros que não tem este botão. Para pegar os e-books que não possuem este botão você deve primeiro entrar na página dele. Caso você já tenha o livro registrado na sua conta, estará aparecendo o botão “ler agora”, do contrário irá aparecer um botão “compre agora com 1-Clique”. Basta clicar nele e o livro será registrado na sua conta.
Mas agora você deve estar se perguntando… Como farei para obter todos esses livros sem precisar clicar no botão “compre agora com 1-Clique” em cada um deles?…
Bom a forma de se obter o livro na primeira ocasião é bem simples… Quando você clica no botão “compre agora com 1-Clique”, seu navegador utiliza a URL referenciada no botão (essa que você pode ver na parte de baixo do navegador ao passar o mouse em cima do botão) para realizar uma requisição HTTP do tipo GET na URL, para falar a verdade toda vez que você acessa uma página da internet o seu navegador realiza uma requisição do tipo GET, pedindo ao servidor que retorne para você um arquivo que é a página HTML do site, existem outros tipos de requisição HTTP que utilizam outros verbos como o POST, PUT e DELETE que são os mais utilizados, e cada um tem sua devida utilidade. O verbo GET significa que você está pedindo ao servidor alguma informação, como por exemplo um arquivo que pode ser uma página HTML. O verbo POST é para quando estamos enviando informações ao servidor e geralmente ele irá registrar essas informações em um banco de dados, como quando você realiza o cadastro em algum site para criar uma conta. O verbo PUT é utilizado para quando vamos atualizar uma informação que já existe no servidor, por exemplo quando você altera o seu número de telefone em uma rede social, e o verbo DELETE como você já deve ter pré suposto, é utilizado para apagar informações, por exemplo uma postagem da sua rede social.
Continuando de onde paramos, a requisição feita pela URL carrega consigo alguns query params, que são estes parâmetros passados após o ponto de interrogação. Caso você tenha a string da URL, poderá separar os query params pelo símbolo de “&” utilizando a função split do javascript. No exemplo exibido no vídeo, você pode ver que é informado nos query params o “ASIN” ou “Amazon Standard Identification Number” que é uma forma criada pela Amazon para identificar seus produtos, é informada também a ação que será realizada para o produto, que é “comprar”, o “gi_csrf”, que é uma identificação única para cada requisição, isso ajuda a Amazon a te proteger contra “Cross Site Request Forgery” ou seja “Falsificação de Solicitação entre Sites”, que é quando uma pessoa mal-intencionada cria um link, uma URL semelhante a esta que está logo abaixo (a informação entre colchetes é um exemplo de informação que poderá estar nos query params da URL):
https://www.amazon.com.br/gp/product/features/glide.html/ref=[RefProduto]?asin=[Cod. ASIN]&action=[buy]&gi_csrf=[Cod. anti CSRF]¤cyCode=[BRL]&price=[0.0]
Esta URL pode estar modificada para que você realize uma operação dentro do site, já que o servidor confia em você por conta dos cookies de autenticação, que são enviados em todas as requests feitas pelo seu navegador. Esses cookies são dados que seu navegador armazena e podem ir desde logins e senhas que te mantém autenticado em sites que você visita regularmente para que não precise colocar o usuário e senha toda vez que você entrar nele, até dados de pesquisas no Google, localização, idioma, tipo de moeda do seu país etc. Para entender melhor como essa vulnerabilidade funciona eu vou utilizar um exemplo que encontrei na Wikipedia.
Suponha que Bob está navegando em um site que tem uma imagem possivelmente inserida através de uma postagem feita por um usuário mal-intencionado chamado Fred. Observe o link contido na tag de imagem a seguir:
<img src=”http://bank.example.com/withdraw?account=bob&amount=1000000&for=Fred">
Nesta imagem foi inserido um link no atributo src com uma requisição feita para o de banco de Bob na intensão de transferir 1 milhão da conta de Bob para Fred, o banco de Bob confia na requisição feita pelo navegador de Fred ao tentar carregar a imagem, pois os Cookies de autenticação de Fred estão armazenados em seu navegador e este automaticamente os envia na requisição.
Se você tentar remover o parâmetro gi_csrf da URL de compra da Amazon, verá que o produto não será comprado pois o servidor verificou que o token csrf não estava presente. Este token é único para cada requisição e é tecnicamente imprevisível, na tela do seu navegador você verá o formato do seu. O próximo parâmetro é o código da moeda que no nosso caso é BRL representando o real, e o preço que é 0.
Vou demonstra como podemos utilizar a API fetch do javascript para realizar uma requisição HTTP de uma forma bem simples. A função fetch recebe a URL por parâmetro e nos retorna uma Promise. Uma Promise é um objeto mágico usado para o tratamento padronizado de processamento assíncrono, ou seja, o funcionamento dela é aguardar até que uma operação seja concluída, vou demonstrar como funciona uma Promisse.
Você vai me ver usar muito as “arrow functions”, elas vieram junto com o ES6 para simplificar a escrita de funções em javascript.
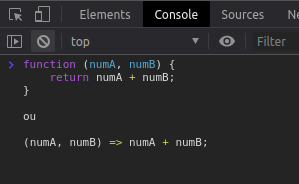
Outro detalhe a considerar é a declaração da função versus o valor de seu retorno.
Neste exemplo vou atribuir a declaração de uma função em uma constante.
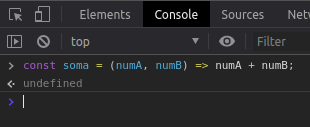
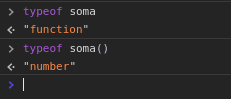
Repare que o tipo do valor da constante soma é exatamente a declaração de uma função, ou seja, podemos dizer que esse valor aponta para algum lugar da memória onde existe um código executável que será avaliado em um valor numérico que é o seu retorno. Quando utilizamos os parêntese acessamos esse valor de retorno, observe.
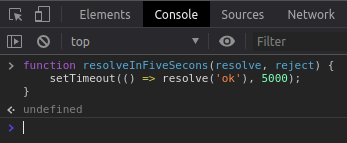
Tendo isso em mente vamos continuar a demonstração do funcionamento das Promises. Vamos declarar uma função que realize uma operação que demora 5 segundos para ser executada, simularemos isso com o setTimeout;
Os parâmetros resolve e reject (que também são funções) serão passados para nossa função no momento da construção da Promise. O resolve é utilizado para quando ocorreu tudo certo durante a execução da Promise e você deseja retornar esse resultado, já o reject é chamado para quando um erro ocorreu e desejamos retornar ele.
A função setTimeout está recebendo dois parâmetros, uma função, que é retornada na declaração da nossa função como você viu anteriormente e um valor inteiro que determina o tempo de espera em milissegundos, nesse caso 5000 milissegundos é o mesmo que 5 segundos.
Agora vamos instanciar uma nova Promise chamada “myPromise” passando uma função para o construtor, como você viu anteriormente, o valor resolveInFiveSecons sem os parênteses está armazenando a função e não o retorno dela então podemos passar a função para o construtor da Promise desta forma.
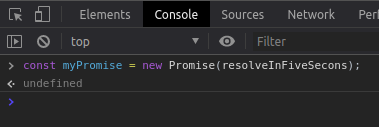
A função then da nossa Promise é chama após a Promise ser resolvida e irá executar outra função que devemos passar por parâmetro para ela. A função catch será executada caso a Promise seja rejeitada (o que nunca acontece neste exemplo) e por parâmetro devemos passar uma função para tratar o erro ocorrido.
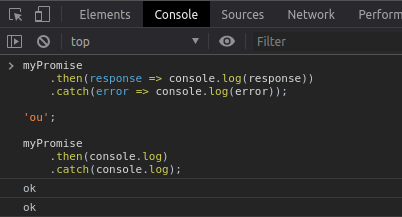
Como já dito a API fetch retorna uma Promise, portanto podemos utilizar a função then e catch para lidar com o resultado ou possível erro retornado pela requisição. Para demonstrar isso vou realizar uma requisição GET na página do Google utilizando a API fetch. Veja abaixo como ficou:
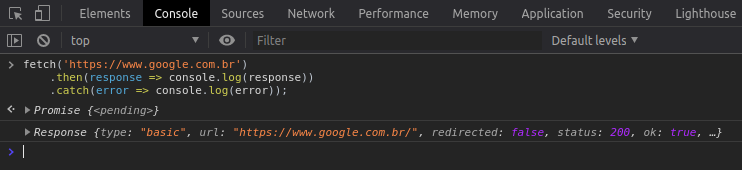
Como você viu o status code retornado foi 200 então ocorreu tudo certo. Os status code fazem parte do protocolo HTTP e todos os status na casa do 200 representam uma resposta de sucesso. Caso você queira saber mais sobre status code, recomendo a leitura deste artigo da MDN que mostra mais sobre os status code do HTTP e seus significados.
Se você abrir uma nova guia e tente executar a requisição GET para uma URL de compra de um e-book da Amazon, será retornado um erro e este erro ocorre porque nossa requisição não está enviando nenhum tipo de autenticação para a Amazon, o servidor da Amazon não poderá confiar em nossa requisição pois os cookies que contém nossa identificação não serão enviados nessa aba e também porque a origem da nossa requisição não foi feita em uma página da Amazon. Portanto para resolvermos isso iremos executar todo o nosso script diretamente em uma página da Amazon.
Agora vou explicar como ele irá funcionar, para os produtos que tem o botão “compre agora com 1-Clique”. Nós iremos rodar um script que selecione todos esses botões e faça um fetch em cada href, então iremos armazenar as URLs que deram certo e as que deram errado para que possamos tentar acessar elas novamente mais tarde, mas dificilmente dará erro, a menos que a página do e-book saia do ar ou algo do tipo, após isso iremos requisitar uma nova página de livros pelo fetch e substituir o body da página da Amazon aberta no navegador, pelo body da nossa página requisitada e assim irá se repetir até que todas as páginas sejam requisitadas.
Para os produtos que não tem esse botão, nós iremos armazenar o link da página deles para mais tarde executar outro script que vai pegar um por um deles pra gente, a maioria dos livros vão ser pegos pela primeira forma. Na página do e-book você pode observar que existe um formulário HTML, este que será enviado para a URL contida na sua action quando você clicar no botão “compre agora com 1-Clique”. O que nós iremos fazer é uma requisição fetch para está página, assim iremos pegar o HTML do form dela e iremos inserir no body da página em que estamos executando esses scripts e depois iremos capturar os dados do formulário e enviar utilizando o fetch.
Partindo para o código, primeiro vamos começar declarando algumas constantes e variáveis que iremos utilizar no nosso script.
A variável pageNumber vai armazenar a página atual em que estamos pegando os e-books, que vai de 1 até 400, nós iremos salvar essa variável no Local Storage que é uma espécie de armazenamento de chave e valor em formato de string no navegador.
Vamos usar o “hackzinho” abaixo para atribuir na variável pageNumber o número da página atual contido no Local Storage se ele existir e transformar em inteiro, já que o Local Storage só armazena string como eu disse anteriormente, se não existir nada no Local Storage o valor atribuído será 1.

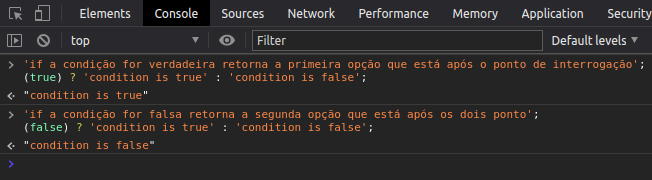
Vamos armazenar em constantes as páginas acessadas e as páginas que falharam ao serem acessadas, aqui vemos o que chamamos de operador ternário, se existir algo no Local Storage me retorne esse algo, no caso uma lista em formato de string e separe ela por vírgula que é o delimitador, como se fosse um CSV (o Local Storage salva um array no formato de string com os itens separados por vírgula), assim será gerado um array de páginas.
Para você entender melhor considere esse exemplo mais simples:

Você deve estar se perguntando, porque eu uso let e const que foram adicionas no ES6 ao invés de var, e a explicação é a seguinte, o var escapa o escopo das variáveis para fora dos blocos e isso pode ocasionar vários problemas, principalmente em aplicações mais complexas, veja este exemplo:
Usando o var a variável “oiDentroDoBloco” e a variável “i” escapam do escopo e são exibidas no console
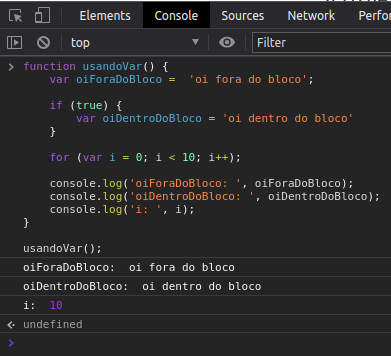
Já usando let isso não ocorre, na verdade irá ocasionar em um erro:
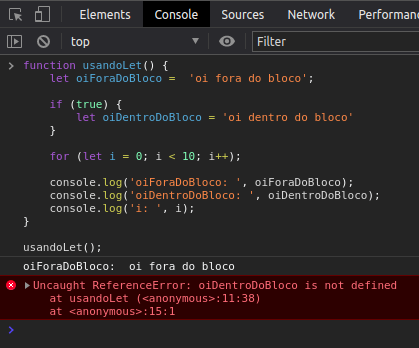
Utilizar o const também mantem o escopo de bloco e traz mais duas vantagens consigo. Primeiro, você deve sempre atribuir um valor a constante e esta não pode mais ser assinada, ou seja, seu valor não vai mudar, e isso traz uma consistência e segurança para sua aplicação além de preservar a imutabilidade. Outra vantagem é que declarar constantes invés de variáveis melhora o desempenho do código, pois o interpretador sabe que esse valor não irá mudar futuramente de int para string por exemplo, e aloca apenas a quantidade de memória necessária para esse inteiro.
Aí você pergunta, tá mas você declarou um array de páginas como constante, porém você irá adicionar mais elementos nela, então ela vai mudar correto? Não exatamente, um protótipo de array é um objeto que possui funcionalidades próprias como, adicionar elementos novos, e isso não vai mudar, no entanto a estrutura é sempre um array, e um array não deixa de ser uma lista encadeada por baixo dos panos. O mesmo se aplica aos objetos JavaScript, você também pode adicionar mais chave-valores nas constantes de objeto, porém ele sempre será um objeto que no final das contas também é uma lista encadeada mas com índices nomeados.
Chega de enrolação e vamos pro código. Todas as variáveis let terão seu valor alterado em cada página de e-books enquanto as consts manterão seu valor em todo o ciclo de vida do script e também serão armazenadas no Local Storage para consultarmos mais tarde ou recuperar o script de onde parou, caso ocorra algum problema como, seu computador desligar durante a execução por queda de energia.

Essa variável irá armazenar a URL de todas as páginas de e-books contidas em nossa página atual, mais tarde vamos comparar um valor único nessas URLs com outro valor único nas URLs dos botões de “compre com 1-Clique” para que possamos descobrir quais e-books não tem esse botão.

Essas variáveis irão armazenas os links contidos nos botões que retornaram sucesso em sua requisição e os que retornaram erro.
Em seguida teremos a constante que vai armazenar o link da página dos e-books que não possuem o botão “comprar com 1-Clique”.

Em seguida vamos obter o elemento body da nossa página atual e substituir todo o seu conteúdo com uma div identificada pelo id “content”. É aqui que sua página ficará em branco. Depois pegamos a referencia para essa div e armazenamos na variável “contentDiv”.

Quando formos capturar todos os botões “comprar com 1-Clique” através dos seletores JavaScript, eles irão nos retornar um NodeList e Node Lists são estruturas iteráveis semelhantes aos Arrays mas não possuem algumas funções importantes como o map, para isso iremos adicionar o map do protótipo do Array no protótipo do NodeList.

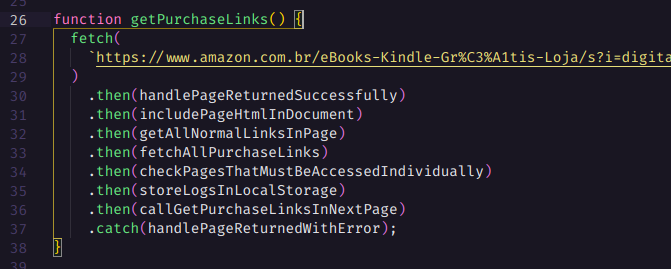
Agora vamos montar toda a estrutura para que possamos obter os e-books.
Primeiro vamos fazer um fetch na primeira página de livros, para isso vamos escrever uma função que use a API fetch do JavaScript para obter a página de livros. Já iremos também escrever uma função para lidar com o sucesso da requisição e com o erro. No sucesso iremos transformar a resposta da requisição em texto, que será o HTML da página, e já vamos registrar que acessamos essa página. No erro iremos registrá-lo também e logar uma mensagem de erro no console.
O link nós iremos pegar da seguinte forma. Se você for para a página 2 por exemplo, verá que existe alguns query params na URL e destes temos um deles que é o “page”, este que indica qual página estamos, então já sabemos que ele deve ser dinâmico, temos o ref que indica de qual página viemos mas podemos tirar ele da URL. Vamos escrever a URL dentro de crases, isso também é chamado de template string e veio junto com o ES6, isso te permite escrever strings interpolando variáveis, repare:
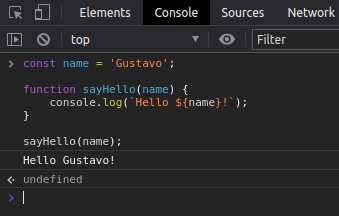
A API fetch retorna uma Promise, e seu valor resolvido poderá ser acessado utilizando a função then, essa que por sua vez também nos retorna uma Promise, isso significa que podemos encadear mais funções then. Vamos então encadear uma função para adicionar o body contido no HTML requisitado dentro da nossa div “content”. E vamos testar para ver se funciona.
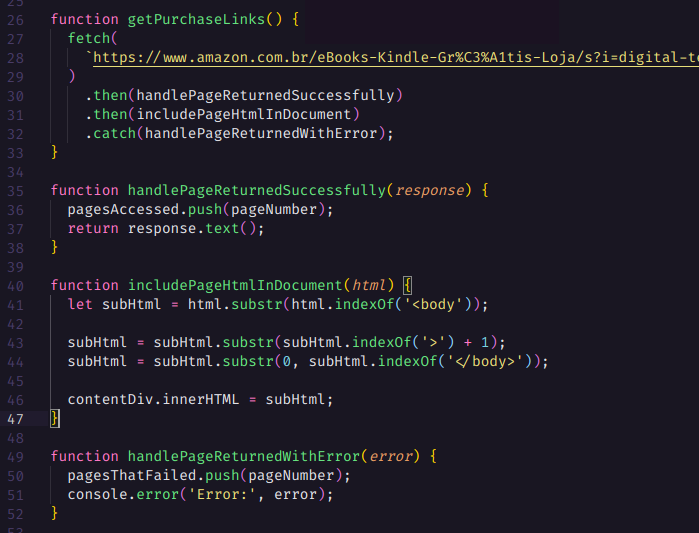
Agora devemos extrair apenas o conteúdo do body, para isso primeiro pegamos uma substring que vai do começo body até o fim do documento, depois pegamos a substring que vai do fechamento da tag de abertura do body até o fim do documento, e por fim removemos todo o final da string a partir do fechamento da tagbody.
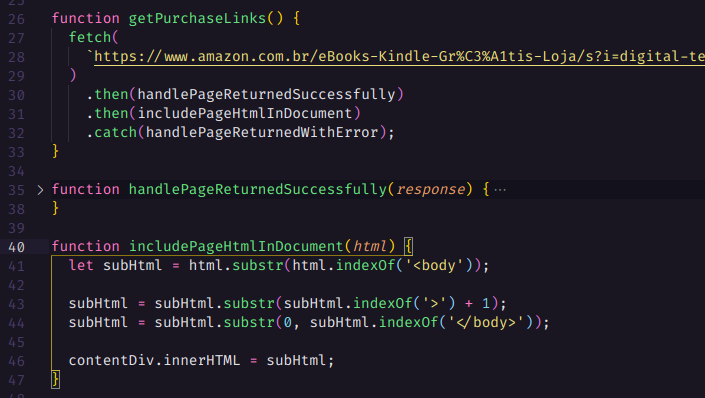
Agora vamos pegar todos os links para a página de cada e-books contidos na nossa página atual. Para isso utilizaremos o document.querySelectorAll que permite fazer uma busca avançada no dom. Aqui estamos pegando todos os links com as classes “a-link-normal a-text-normal” contidos dentro do h2 que representa o título de cada livro.
Antes de continuarmos deixa eu te explicar algumas coisas rapidamente. Observe a ordem da sequência de logs abaixo:
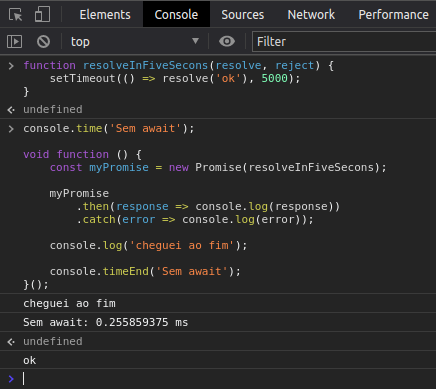
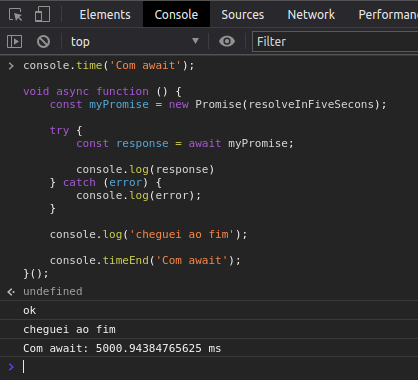
Você reparou que a mensagem “cheguei ao fim” foi exibida antes da Promise retornar o “ok”? Agora como faremos para o JavaScript esperar a função assíncrona da Promise ser executada antes de continuar executando o código? Podemos usar o async e await também introduzidos no ES6. Veja.
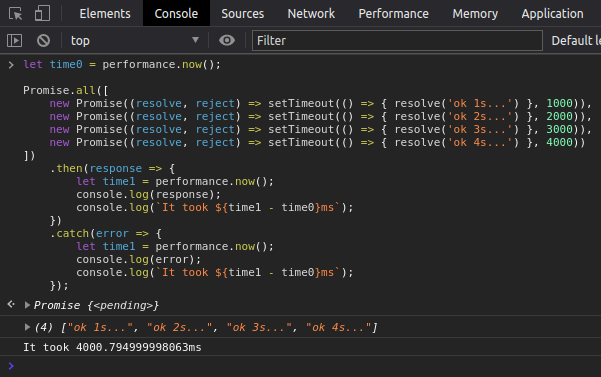
O objeto Promise possui várias funções, uma delas é a Promisse.all, esta função aceita como parâmetro um array de Promises e espera até que todas elas sejam resolvidas ou alguma seja rejeitada para retornar uma Promise, observe, que se todas estas funções demorariam 10 segundos mas utilizando Promises em paralelo podemos notar que a execução de todas elas levou quase o mesmo tempo que a Promise mais demorada leva para executar ou seja 4 segundos. Existe também a função Promisse.race que retorna uma Promise assim que a primeira Promise da lista seja resolvida ou rejeitada. Nós iremos utilizar a função Promise.allSettled que retorna uma Promise assim que todas as Promises passadas para esta função sejam resolvidas ou rejeitadas, as Promises do array serão as requisições para cada URL do botão “comprar com 1-clique”, assim se alguma requisição for rejeitada as outras continuarão executando.
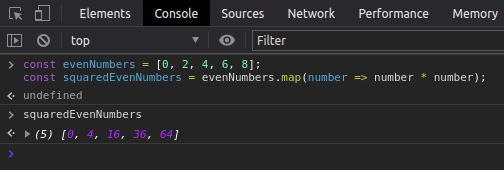
Outra coisa importante para lembrar é a função map que faz parte do protótipo do objeto Array, ela executa uma função para cada elemento do array e ao fim retorna um novo array modificado sem alterar o array mapeado. Isso é outro fator importante da imutabilidade. Veja esse exemplo, declaramos um array com 5 números pares, declaramos um novo array que vai receber os números pares ao quadrado, utilizados a função map para mapear o array de números pares e retornar um novo array de números pares elevados ao quadrado.
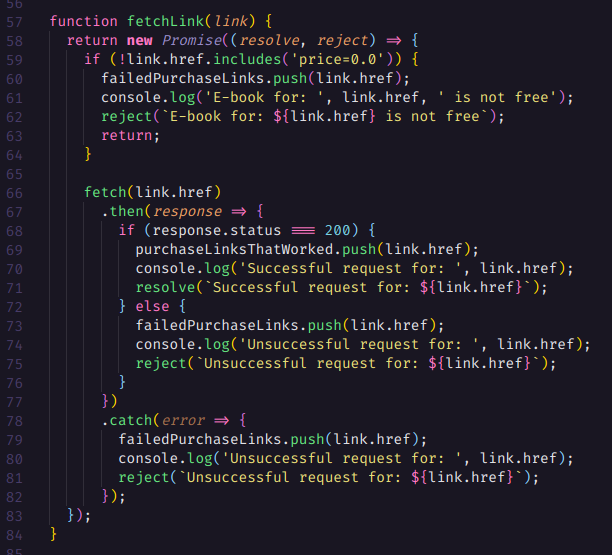
Continuando de onde paramos… Primeiro vamos criar um array de links que estão contidos nos botões “comprar com 1-Clique” chamado buttonLinks. Para isso vamos utilizar uma nova consulta avançada que obtém os links em que o seu atributo href comece com “/gp/product/”. E então, iremos percorrer cada link contido em buttonLinks, utilizando a função map, e retornar uma Promise para este link, com a finalidade de requisitar o link e registrar os links que deram certo ou falharam caso o fetch resolva ou rejeite a requisição. Essa Promise é retornada pela função fetchLink. Observe:
Depois iremos chamar requisições para todas as URLs utilizando o await e Promise.allSettled para esperar todos os links serem resolvidos ou rejeitados e então podemos avançar para a próxima etapa... Observe que a função abaixo começa limpando a lista de links que falharam ou funcionaram na página anterior, pois iremos percorrer eles e não precisamos percorrer links de páginas anteriores, já que estes foram percorridos antes.
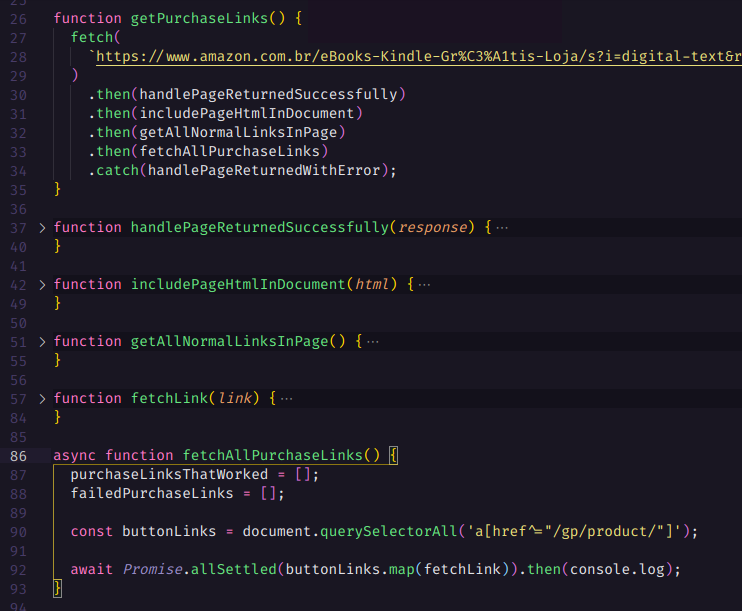
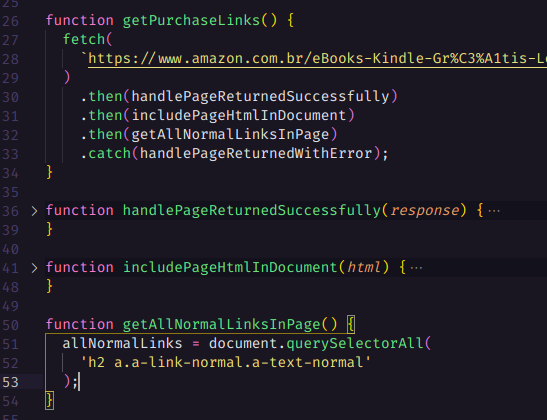
Devemos então checar quais e-books não tinham o botão “comprar com 1-Clique” para registrar o link da página deles, iremos utilizá-los mais tarde com outro script para enviar os formulários de cada página de e-book.
Primeiro vamos percorrer todos os links de página de e-books que são obtidos novamente em cada página de livros que estivermos, para cada elemento nós iremos pegar da URL o parâmetro asin (“Amazon Standard Identification Number” que é uma forma criada pela Amazon para identificar seus produtos, já comentada anteriormente) pois esse código é único e também está contido na URL dos botões.
Após isso iremos percorrer cada link de botão que obteve sucesso e iremos obter os query params para cada botão, pois dentre eles também está o asin, em sequencia iremos verificar se o asin do ebook está contido na string dos query params de algum dos botões desta página e caso não esteja este será incluído no array de páginas de e-books para serem acessados individualmente pelo nosso próximo script depois.
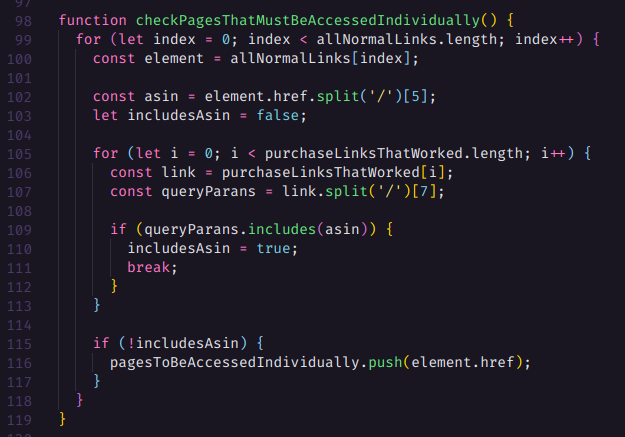
O próximo passo é registrar todas as constantes no Local Storage para que possamos monitorar a cada página visitada, todos os links que deram certo e falharam, além é claro de armazenar a página atual. Desta forma além de ter um log de tudo, também podemos recuperar a execução no script da página onde parou, e mantendo todo o histórico de links que obtiveram sucesso ou falha.
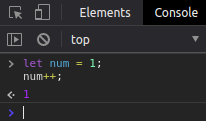
Por fim basta incrementarmos o número da página e chamar a função que executará tudo novamente, e ainda temos um novo conhecimento aqui. Existem diferenças entre pageNumber++ e ++pageNumber observe.
Se você utilizar o incremento após o nome da variável, então ela será retornada e depois será incrementada.
Já quando você utiliza o incremento antes do nome da variável ela primeiro será incrementada e depois retornará o valor já incrementado.
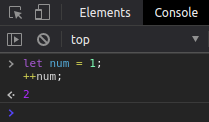
Isso faz toda diferença no momento de utilizar comparações junto com incremento de variável.
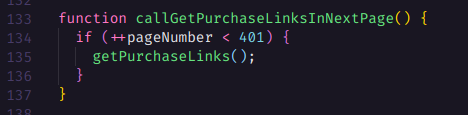
Nossa sequência de operações ficou assim:
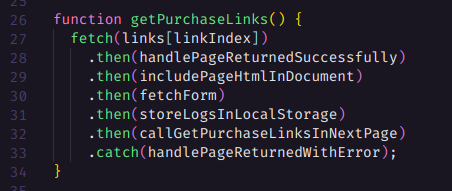
Para os e-books que precisam ser obtidos individualmente, o script é quase igual porém mais simples e com alguns detalhes diferenciados, começando pelos links que virão dos links de páginas individuais dos e-book que não tinham botões, armazenados no Local Storage.

Invés de pageNumber temos agora o índice do link no array de links.

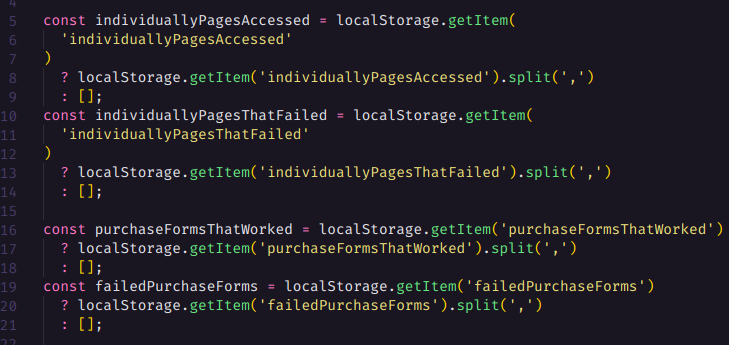
E temos as variáveis que farão todo o log de páginas acessadas e formulários enviados.
Adicionamos a div content no body da página.

Essa é a função que irá requisitar o HTML da página.

A seguir temos a função que irá buscar o formulário que contém os dados de compra do ebook e inserir o html dele na nossa div content.

Iremos então selecionar este form pelo id e obter o FormData dele utilizando um construtor de FormData e passando o formulário como parâmetro do construtor, este FormData é um objeto que contém os dados do nosso formulário e pode ser passado para o body da nossa requisição que agora não é mais do tipo GET e sim do tipo POST.
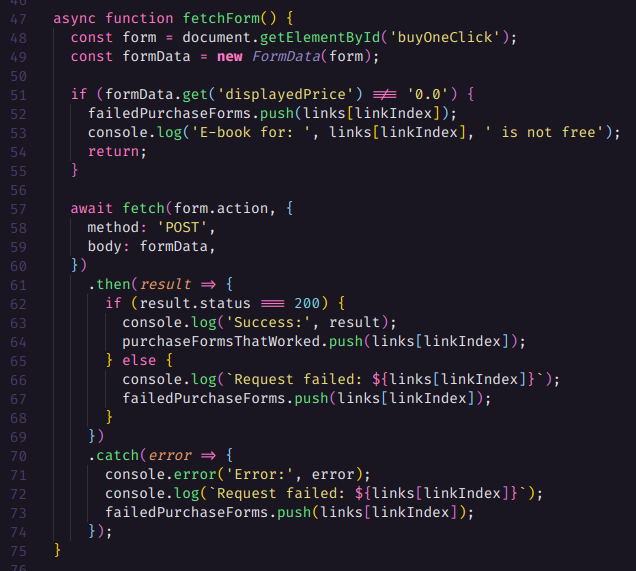
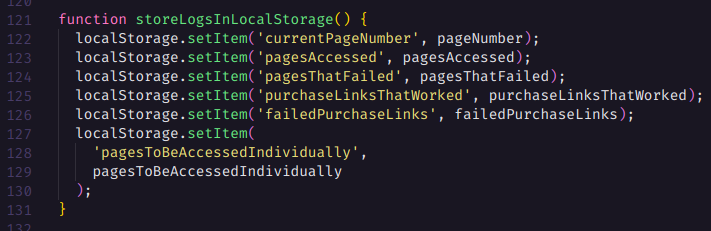
Em seguida armazenamos todas as contantes no Local Storage
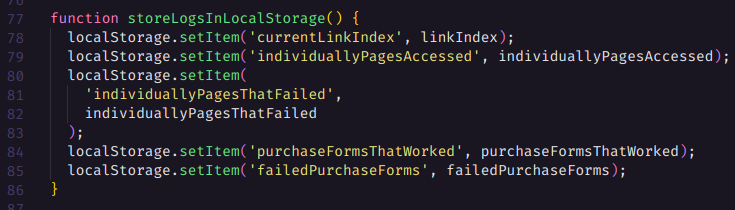
E avançamos para a próxima página.
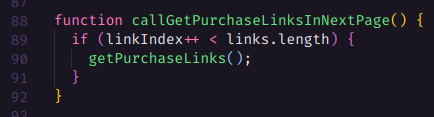
O passo a passo das operações ficou assim:
Vou deixar todo o código desses scripts no meu GitHub, você pode acessar o repositório neste link: https://github.com/gustavo-tp/amazon-ebook-taker.
Se você ficou bravo porque queria apenas o código, se sinta melhor, pois você aprendeu muito lendo esse artigo e/ou assistindo ao vídeo e isso era o mais importante, os livros gratuitos são só um bônus.
Vale salientar que os livros comprados são baixados diretamente para o seu dispositivo padrão e até o momento não identifiquei um modo de cancelar isso, caso você tenha pouca memória disponível, pode ser que o seu aplicativo do Kindle trave. Uma sugestão é esperar que os livros sincronizem e então reinstalar o Kindle, isso excluirá os livros baixados automaticamente e você poderá baixar depois apenas os quais quiser ler.
Caso você verificou um erro ou algo que poderia ser melhor no script não deixe de fazer um Pull Request no meu repositório, e se você sabe uma maneira melhor de fazer isso, seja com Python, Ruby, WebDriver ou qualquer outra forma, por favor deixe nos comentários que eu com certeza vou ler. Qualquer dúvida não deixem de comentar também, tando no vídeo quanto aqui, assim que puder estarei respondendo e suas dúvidas podem ser as de outros, além é claro de estar adicionando mais conhecimento a esse conteúdo.
Obrigado por ter lido até aqui, se você gostou do post ou vídeo dá uma palma ou jóinha. Se quiser sugerir novos temas para futuros vídeos ou que eu explique alguma coisa que apresentei neste post/vídeo, mas de forma mais profunda também não deixe de comentar. Obrigado e até a próxima!